MySQL 作业
MySQL 作业
题目 1
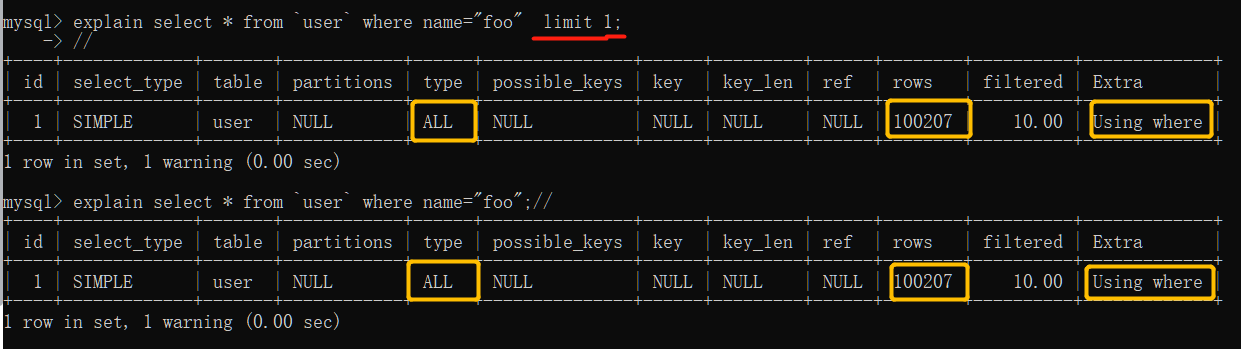
1.满足 WHERE 条件的数据有 10W 行,请问这个时候使用 LIMIT 1 来进行查询时,需要扫描多少行数据?为什么?
通过打印执行计划发现,使用 LIMIT 1 进行扫描行数是 100207
SQL 语句执行顺序:
FROM => ON => JOIN => WHERE => … => LIMIT
原理:在实际 SQL 语句执行过程中,是由 FROM 开始, 每个步骤都会为下一步骤生成一个虚拟表,再执行 LIMIT 之前先执行 WHERE,通过执行计划 using where发现, limit 1 查询时并没有找到可用的索引,从而只能通过 WHERE 条件过滤获取结果。
题目 2
2.判断在不同的 SQL 语句中使用 AS 别名是否正确?为什么?
1 | |
在 MySQL 中,
WHERE错误 ;GROUP BY正确
原理:
在标准 SQL 语句执行顺序下, WHERE 和 GROUP BY 都是不可以使用别名的
FROM => ON => JOIN => WHERE => GROUP BY => … => SELECT => …
但是,MySQL 下 GROUP BY 是可以的, 原因是 MySQL 对查询进行加强
题目 3
3.如果表 T 中没有字段 k,而你执行了这个语句 select * from T where k=1,那肯定是会报“不存在这个列”的错误:“Unknown column 'a' in 'where clause'”。那么这个错误是在我们上面提到的哪个阶段报出来的呢?
分析器阶段报错
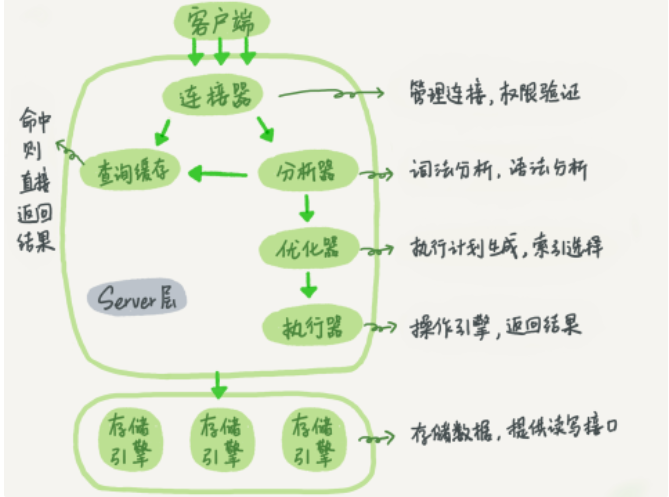
原理:在 MySQL 的 server 层中, 分析器会对 SQL 语句进行词法分析,语法分析,语义分析,其中:
词法分析:分析 SQL 语句中的字符串代表什么,生成解析树。如将字符串转换为表、列等…
语法分析:根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。 如通过关键字 select 得知是一条查询语句
预处理器:对 SQL 中的表,字段等内容检查是否存在,如 xx 表是否存在,xx 表 xx 列是否存在
由此可见,当表 T 中没有字段 k 不存在时,在分析器阶段的预处理器阶段就会报错
题目 4
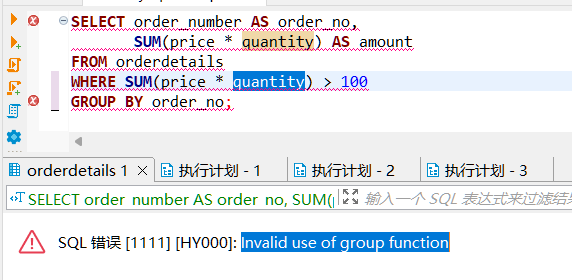
4.以下 SQL 是否会异常?如果异常,那么正确的应该怎么写?
1 | |
上述 SQL 是错误的
建表语句:
1 | |
验证过程:
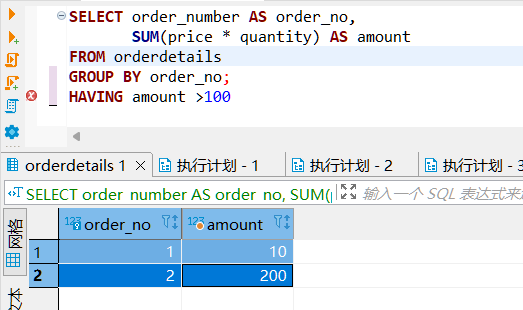
不难发现,因为在 WHERE 子句中使用了 group function 导致报错,因为在 SQL 语句执行过程中,WHERE 执行是要比 AGG_FUNC 要早,导致在执行 WHERE 无法识别聚合函数导致报错。
正确写法:
HAVING 子句是在 AGG_FUNC 步骤之后, 所以使用其代替 WHERE 进行判断
1 | |
题目 5
5.为什么要使用数据库连接池?连接池如何保活?
数据连接池主要作用让数据库连接得到复用,避免了频繁建立,释放连接而产生大量性能和时间消耗,提升数据库性能和缩短响应时间。另一方面还可以统一管理连接,防止数据库连接泄漏导致的安全的隐患。
连接池保活机制,业务代码在低峰时会降低 get()动作,所以连接池中的连接在长时间不用时会导致失效,此时保活线程在监测到 get()的使用频率较低时,会模拟业务程序调用 get()获取连接后发送心跳包,然后再通过 free()将被保活的连接放回队列中,达到连接池中所有连接保活的目的。
题目 6
6.以下两条 SQL,假设字段都不存在索引的前提下:
- 哪个性能更好?为什么?
- 这两条语句的执行过程。
1 | |
- 打印执行计划发现:
第一条 SQL 语句

第二条 SQL 语句

第二条 SQL 性能会更好,前者总共执行 4 个步骤,而后者总共执行 3 个步骤
两条语句的执行过程
第一条 SQL 语句
a.执行 FROM 获取数据表,生成虚拟表 vt1
b.执行 GROUP BY 操作,按照列名 a 进行分组 => vt2
c.执行 SLELECT 操作,按照列名 a 进行选取操作 => vt3
d.执行 ORDER BY 操作,生成游标 vc4
第二条 SQL 语句
a.执行 FROM 获取数据表,生成虚拟表 vt1
b.执行 SLELECT 操作,按照列名 a 进行选取操作 => vt2
c.执行 DISTINCT 操作,根据列名 a,去重 => vt3
题目 7
7.什么样的表,适合使用查询缓存?为什么?
一般来说,数据相对稳定、不常更新的表适合使用查询缓存。 因为这类数据表不需要常常的更新,更多起到一个查询的作用。若遇到频繁的请求时,通过查询缓存,命中则直接返回结果集,从而减少 SQL 执行次数,优化 SQL 的性能。
具体举例,比如地理区域数据表,区域代号这类数据表等等
比如在某电商平台,有个地址管理,用户可以通过选择省市区存储自己的地址,而 省市区这些地址,往往是不需要频繁更新的,起到往往是标识和选择的作用,所以用户在选择省市区联动时,会频繁查询省市区数据表,经过查询缓存步骤时,到查询引用表,通过一个哈希值(查询的数据库,客户端协议,查询本身等),判断是否命中(对比原始 SQL 语句,所以任何字符上的不同,例如空格,注释等都会导致缓存不会命中),假若命中,则直接返回缓存中的结果,否则正常走执行 SQL 语句。
题目 8
8.以下 SQL 会报什么错?是在分析器哪个步骤抛出的错误?
1 | |
词法分析阶段报错
分析器执行过程:
词法分析:分析 SQL 语句中的字符串代表什么,生成解析树。如将字符串转换为表、列等…
语法分析:根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。 如通过关键字 select 得知是一条查询语句
预处理器:对 SQL 中的表,字段等内容检查是否存在,如 xx 表是否存在,xx 表 xx 列是否存在
由此可见,当 SQL 语句,执行到词法分析时,发现无法解析 elect 这个字符串,而从无法生成解析树
题目 9
9.对以下 SQL 进行优化器分析,会出现哪些情况?
1 | |
a.t1 和 t2 都无索引时,各 100 条数据

b.t1 和 t2 都无索引时,各 10w 条数据

c.t1(添加),t2 其中一个有索引,各 100 条数据

d.t1(添加),t2 其中一个有索引,各 10w 数据

e.t1,t2 都有索引,各 100 条数据

f.t1,t2 都有索引,各 10w 条数据

g.当 t1 数据量大于 t2 数据量

h.当 t2 数据量大于 t1 数据量

分析可得:
默认情况:(数据量一致,无索引)
1.选择 join 关键字前面的表作为驱动表
当 t1, t2 其中一个拥有索引
1.数据量少,优化器选择其中有索引一方(数据表),作为驱动表
2.数据量大,优化器选择其中有索引一方(数据表),作为驱动表,随着数据量增大,扫描 rows 越少
当 t1, t2 都拥有索引
1.选中数据量少的一方(数据表),作为驱动表
2.数据量一致,选择默认 join 关键字前面的表作为驱动表
总结:
MySQL 优化器是基于成本来选择最优执行方案的,哪个成本(rows)最少选哪个
数据量大的时候,适当使用索引可以,减少扫描成本
题目 10
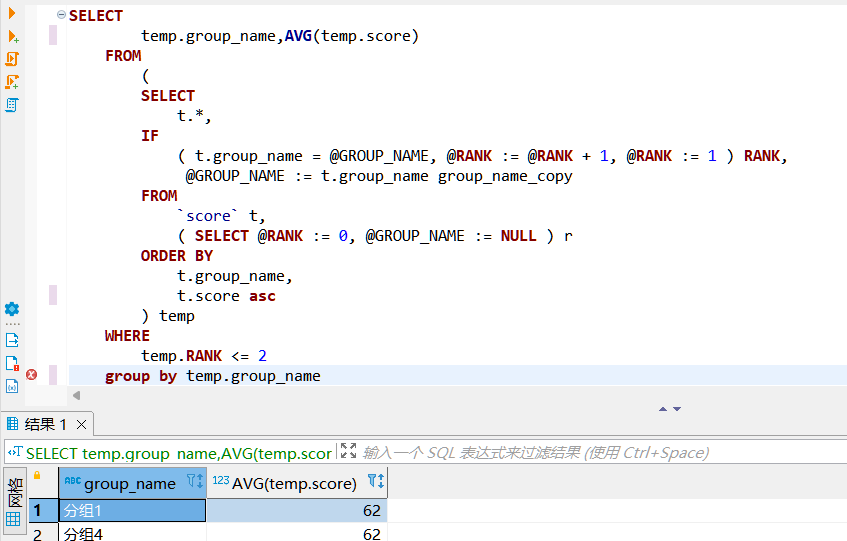
10.如下表,请编写 SQL,完成以下题目:
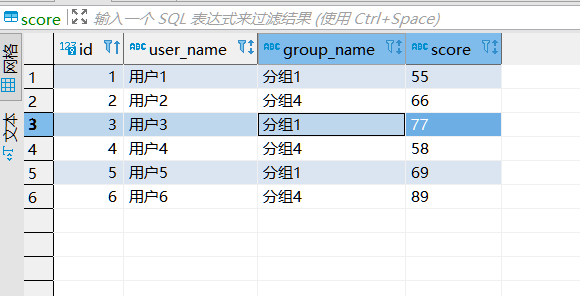
score 表数据如下:
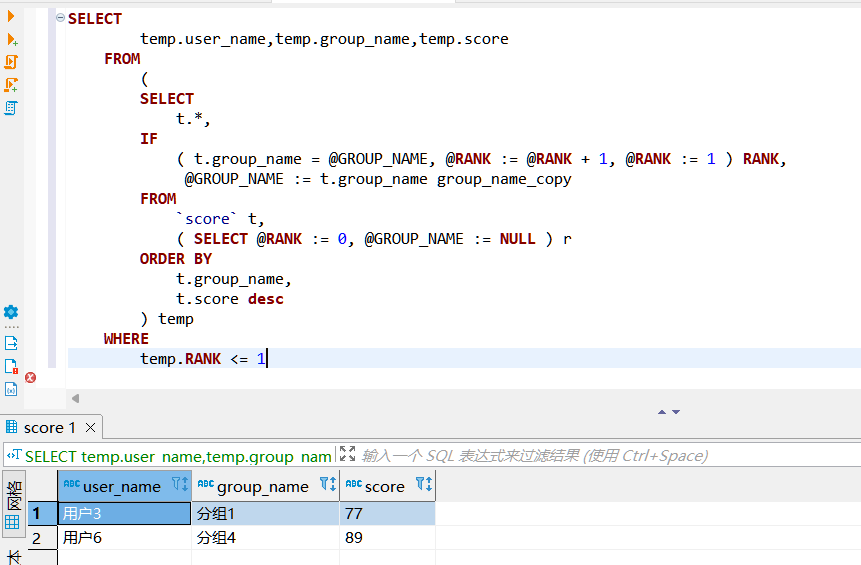
1.从每个分组中找到分数排名第一的用户;
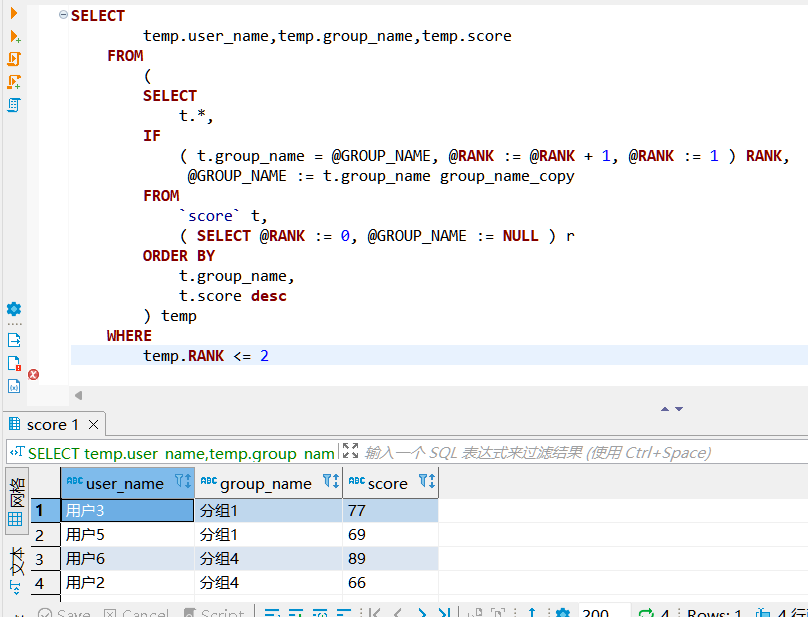
2.从每个分组中找到分数排名前二的用户;
3.获取每个每组下最后两名分数的平均值;
题目 11
11.如果用 left join 的话,左边的表一定是驱动表吗?请举例说明。
不一定,下方举个栗子
创建两个结构相同的表 t1 和 t2 ,其中表 t1 的 c 字段有索引,而表 t2 没有
分别执行两个不同 SQL 语句
1 | |
打印 explain:
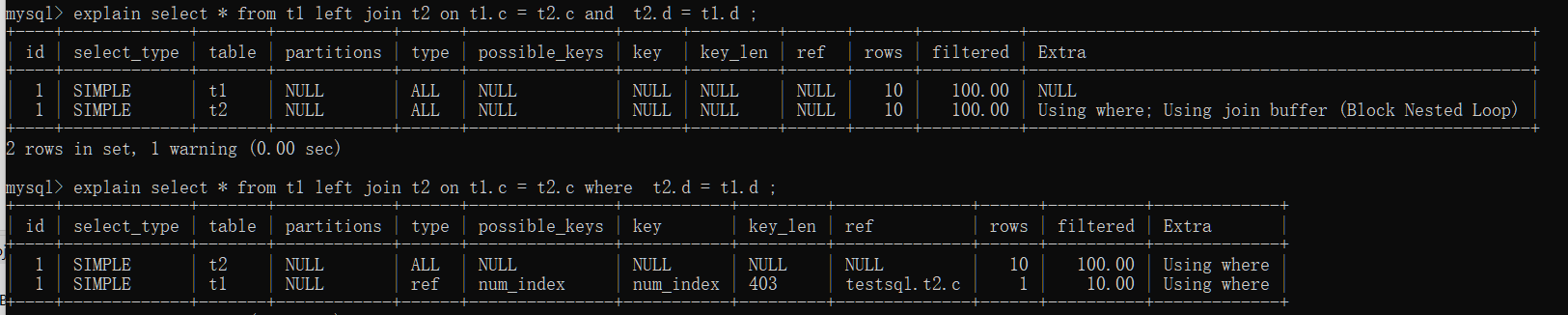

可以发现,当把被驱动表的字段放在 where 条件里面做等值判断或不等值判断,会使得 left join 关键字右边 t2 作为驱动表。
通过 show warnings, 可以看到,MySQL 优化器把这条语句的 left join 改写成了 join,然后因为表 t1 的 c 上有索引,就把表 t2 作为驱动表,这样就可以用上表 t1 的 c 索引。
课外题
课程中,详细讲述了一条查询 SQL 是如何执行的,那么,一条更新 SQL 又是如何执行呢?

MySQL 通过哪个参数可以设置不使用查询缓存?
查询时增加一个 SQL_NO_CACHE 指令
1
SELECT SQL_NO_CACHE field_1, field_2, ... from table_1;
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!